ABSTRACT
The past decade has been witnessing an explosion of various applications and devices. This big-data era challenges the existing security technologies: new analysis techniques should be scalable to handle “big data” scale code base; They should be become smart and proactive by using the data to understand what the vulnerable points are and where they locate; effective protection will be provided for dissemination and analysis of the data involving sensitive information on an unprecedented scale.
In this dissertation, I argue that the code search techniques can boost existing security analysis techniques (vulnerability identification and memory analysis) in terms of scalability and accuracy. In order to demonstrate its benefits, I address two issues of code search by using the code analysis: scalability and accountability. I further demonstrate the benefit of code search by applying it for the scalable vulnerability identification and the cross-version memory analysis problems.
Firstly, I address the scalability problem of code search by learning “higher-level” semantic features from code. Instead of conducting fine-grained testing on a single device or program, it becomes much more crucial to achieve the quick vulnerability scanning in devices or programs at a “big data” scale. However, discovering vulnerabilities in “big code” is like finding a needle in the haystack, even when dealing with known vulnerabilities. This new challenge demands a scalable code search approach. To this end, I leverage successful techniques from the image search in computer vision community and propose a novel code encoding method for scalable vulnerability search in binary code. The evaluation results show that this approach can achieve comparable or even better accuracy and efficiency than the baseline techniques.
Secondly, I tackle the accountability issues left in the vulnerability searching problem by designing vulnerability-oriented raw features. The similar code does not always represent the similar vulnerability, so it requires that the feature engineering for the code search should focus on semantic level features rather than syntactic ones. I propose to extract conditional formulas as higher-level semantic features from the raw binary code to conduct the code search.
A conditional formula explicitly captures two cardinal factors of a vulnerability: 1) erroneous data dependencies and 2) missing or invalid condition checks. As a result, the binary code search on conditional formulas produces significantly higher accuracy and provides meaningful evidence for human analysts to further examine the search results. The evaluation results show that this approach can further improve the search accuracy of existing bug search techniques with very reasonable performance overhead.
Finally, I demonstrate the potential of the code search technique in the memory analysis field, and apply it to address their across-version issue in the memory forensic problem. The memory analysis techniques for COTS software usually rely on the so-called “data structure profiles” for their binaries. Construction of such profiles requires the expert knowledge about the internal working of a specified software version. However, it is still a cumbersome manual effort most of time.
I propose to leverage the code search technique to enable a notion named “cross-version memory analysis”, which can update a profile for new versions of a software by transferring the knowledge from the model that has already been trained on its old version. The evaluation results show that the code- search based approach advances the existing memory analysis methods by reducing the manual efforts while maintaining the reasonable accuracy. With the help of collaborators, I further developed two plugins to the Volatility memory forensic framework, and show that each of the two plugins can construct a localized profile to perform specified memory forensic tasks on the same memory dump, without the need of manual effort in creating the corresponding profile.
BACKGROUND
This chapter presents a survey of existing code search techniques and its applications to better understand the capabilities and limitations of these prior works. It also provides an understanding of how the state of the art in the code search technique is advanced by the design of our proposed approaches.
- Feature Engineering in Code Search
- Similarity Metrics in Code Search
- Applications in Code Search
SCALABLE AND ACCOUNTABLE CODE SEARCH PLATFORM

Fig. 3.5 : The overview
The inputs are binaries of ssl get algorithm 2 function for x86 and MIPS, which contains the vulnerability CVE-2013-6449. First, the two binaries are lifted into an intermediary representation (IR). Second, conditional formulas are extracted from the lifted binary function. Finally, the conditional matching works for the similarity score, and one-to-one mapping results are outputted.

Fig. 3.6.: The example of the code translation for the call instruction
Figure.3.6 shows a concrete example of how to translate a call on both x86 and MIPS architecture. In this example, from the analysis in IDA, I know that the function bar has two parameters, so at the call site, call bar and jal bar will be translated into a number of IR instructions shown on the right hand side of the figure. Instructions before the call instruction describe how arguments are passed into the corresponding function.
APPLICATION I: SCALABLE VULNERABILITY SEARCH IN IOT DEVICES
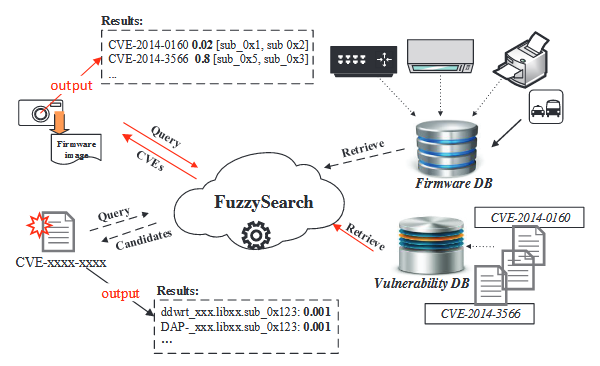
Fig. 4.1: The deployment of GENIUS
Figure 4.1 shows two use scenarios for GENIUS. 1) Scenario I : Given a device repository, GENIUS will index functions in the firmware images of all devices in the repository based upon their CFGs. When a new vulnerability is released, a security professional can 48 use GENIUS to search for this vulnerability in their device repositories. GENIUS will generate the query for the vulnerability and query in the indexed repository. The outputs will be a set of metadata about all potentially infected devices with their brand names, library names and the potentially vulnerable functions. All outputs will be ranked by their similarity scores for quick screening of the results.
2) Scenario II : Security professionals may upload unseen firmware images that do not exist in the repository for a comprehensive vulnerability scan. In this case, GENIUS will index these firmware images for the security professionals. As a result, they can simply query any vulnerabilities in our vulnerability database. GENIUS will retrieve the most similar vulnerabilities in the existing indexed firmware images and output metadata of all potentially vulnerable functions including their names, library names holding these functions and firmware device types where these functions are used. Again, all outputs will be ranked by their similarity scores to facilitate quick screening of the results.
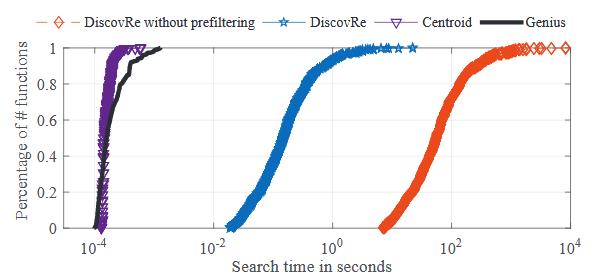
Fig. 4.3: The CDFs of search time on Dataset I
Similar to the accuracy comparison discussed above, I evaluated the online search efficiency on Dataset I and II, respectively. I first conducted the search on Dataset I, searched all of the functions in the dataset and recorded their search times for each target approach. Fig.4.3 lists the Cumulative distribution function (CDFs) of search time for the four approaches on Dataset I, where the x -axis plots the search time in seconds. We can see that GENIUS and the centroid based approach have least search time.
APPLICATION II: ACCOUNTABLE BUG SEARCH IN BINARY PROGRAMS

Fig. 5.2 : The cross-platform baseline comparison on 1,000 functions randomly selected from the dataset
In the second experiment, I randomly selected 1,000 functions without considering their sizes, and applied all mentioned approaches on this dataset. For each method, I also collected its recall rates for different threshold K. Figure.5.2 shows the comparison results. We also can see that X MATCH can still outperform all baseline methods.
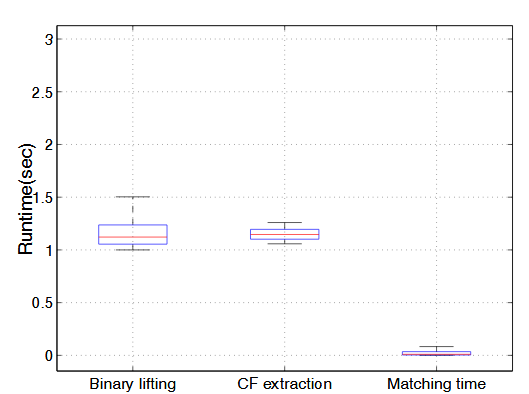
Fig. 5.4 : The run time performance of X MATCH
The results are presented in Figure 5.4. On average, the binary lifting and conditional formula extraction take 2.3 seconds, and it takes 0.029 seconds to perform the function level matching. Overall, no matching takes longer than 0.55 seconds for all functions. The maximum preprocessing time (binary lifting and conditional formula extraction) is about 2.9 seconds. The preprocessing can be easily executed in parallel across multiple machines, and thus is not the bottleneck of our system.
APPLICATION III: ACROSS-VERSION MEMORY ANALYSIS
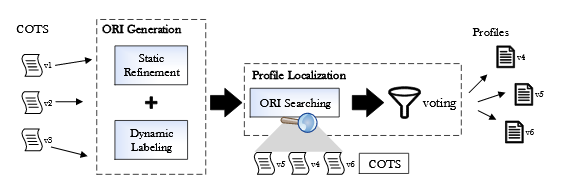
Fig. 6.2 : The overview of ORIGEN
I have developed a prototype system called ORIGEN and evaluated its capability on a number of software families including Windows OS kernel, Linux OS kerne, and OpenSSH. Particularly, I systematically evaluate it on 40 versions of Open SSH, released between 2002 and 2015. The experimental results show that ORIGEN can achieve a precision of about 90% by transferring relevant knowledge in the profile of a different version automaically. The results suggest that ORIGEN advances the existing memory analysis methods by reducing the manual efforts while maintaining the reasonable accuracy.
I utilize a running example in Figure 6.2 to demonstrate our problem. Although I target at the memory analysis for the COTS software, for clarity, I utilize the open-source software OpenSSH to demonstrate our basic idea. Figure 6.2 shows code snippets for two versions of Open SSH, where several highlighted instructions are used to access ssh1 key and ssh1 keylen fields in the structure of session state, and a global variable active state, which points to the structure session state. The constant values carried by these instructions indicate the exact offsets of these fields inside the data structure. Therefore, these highlighted instructions are ORIs.
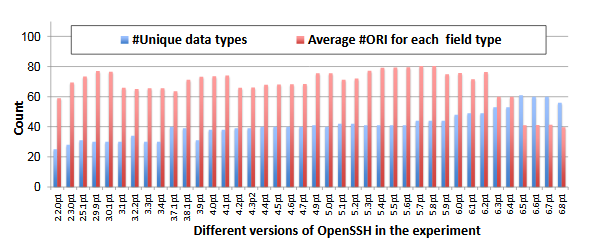
Fig. 6.5 : The statistics of the data types and the average number of ORIs to the field type in the Open SSH dataset
The experimental set is representative for the following reasons: 1) the set is a sufficient sampling of real-word softwares. The versions in our experiments cover a span of 13 years of OpenSSH, from 2.2.0p1 in 2002 to 6.8p1 in 2015; 2) the data types and the structs in OpenSSH are rich and representative. For example, there are 1,904 structs and 22,618 fields in total for 40 versions of OpenSSH. Figure 6.5 illustrates the number of unique data types in each version.
SUMMARY AND FUTURE WORK
In the era of explosion of applications and devices, the security analysis technique faces the “ big data” challenge. Firstly, discovering vulnerabilities in millions of applications or devices is like finding a needle in a haystack, even when we are dealing with known vulnerabilities. Secondly, the memory analysis could be required to handle hundreds of memory dumps at one time. The existing memory analysis tools could not keep up with handling memory dumps on an unprecedented scale.
The fundamental problem of existing vulnerability identification and memory analysis techniques lies in that they are not scalable. The thesis of this work is that scalable and accountable code search technique enhances the efficiency and accuracy of vulnerability identification and memory analysis via an effective data reduction and knowledge reuse.
To address the challenges I discussed before, I propose a scalable and accountable binary code search framework. It can search the code in the large code database with the real-time efficiency, and also provide the search explanatory to aid analysts for match result inspection. To address the scalability issue in the binary code search, instead of comparing binary code with “raw features”, I adopt the machine learning approach to learn “high-level” numeric features from raw features without the loss of essential semantic information.
Source: Syracuse University
Author: Qian Feng
>> Latest 50+ IoT based Security Projects for Engineering Students
>> IoT based Big Data and Cloud Computing Projects for B.E/B.Tech Students
>> 200+ IoT Led Projects for Final Year Students
>> IoT Software Projects for Final Year Students