ABSTRACT
The emergence of new horizons in the field of travel assistant management leads to the development of cutting-edge systems focused on improving the existing ones. Moreover, new opportunities are being also presented since systems trend to be more reliable and autonomous. In this paper, a self-learning embedded system for object identification based on adaptive-cooperative dynamic approaches is presented for intelligent sensor’s infrastructures.
The proposed system is able to detect and identify moving objects using a dynamic decision tree. Consequently, it combines machine learning algorithms and cooperative strategies in order to make the system more adaptive to changing environments. Therefore, the proposed system may be very useful for many applications like shadow tolls since several types of vehicles may be distinguished, parking optimization systems, improved traffic conditions systems, etc.
OVERALL SYSTEM
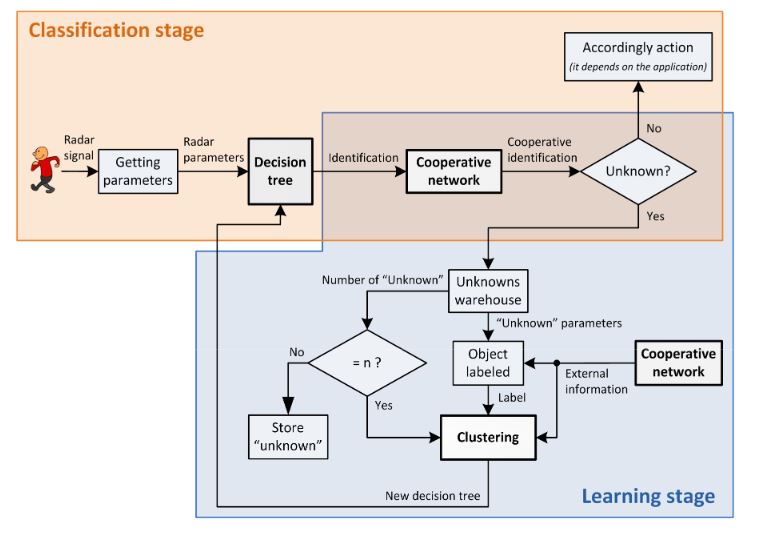
Figure 1. Whole scheme of the proposed system
On the one hand, cooperation will provide more reliability since it allows make a joint decision taking into account different hypo thesis over the same object. Moreover, on the other hand, a dynamic classification tree is proposed in order to adapt the system behavior to some environment changes using also the cooperative network and some clustering techniques. The whole scheme of the proposed system is shown in Figure 1 where two different stages are defined.
MATERIALS AND METHODS
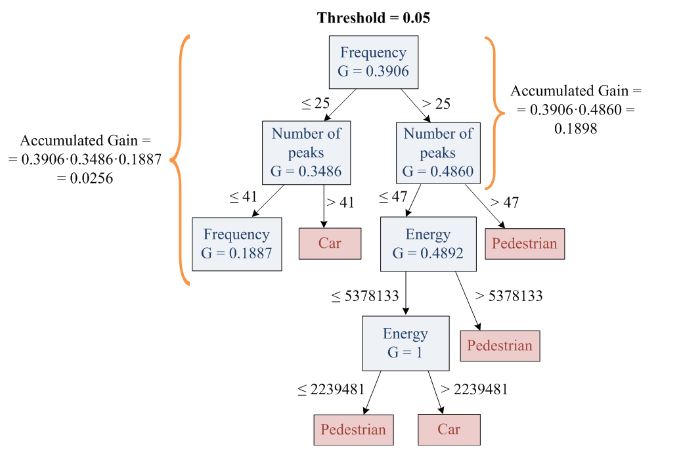
Figure 3. Pruning process
Additionally, pre-pruning is in charge of providing the system with self-learning capabilities, i.e., the decision tree is created from the top to the bottom and for every node of the decision tree, the gain ratio (GR) is computed. The cumulative product of the gain ratio (GR) of all the upper decision tree levels is called accumulated gain (AG). If the accumulated gain (AG) is greater than the threshold (pruning threshold), the decision tree will continue growing. In other case, the decision tree will be pruned (Figure 3).
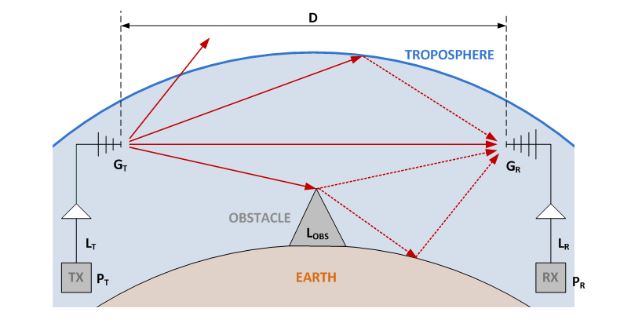
Figure 5. Signal transmission model in an outdoor environment with obstacles
Figure 5 shows the signal propagation model for outdoors scenarios and illustrates how the sending signal is propagated in any direction and the received antenna receives direct and bounced signals. However, as that figure shown, part of the signal does not reach the received antenna. Therefore, the Friis formula is useful to calculate how far the nodes can be placed to ensure reliable links.
RESULTS
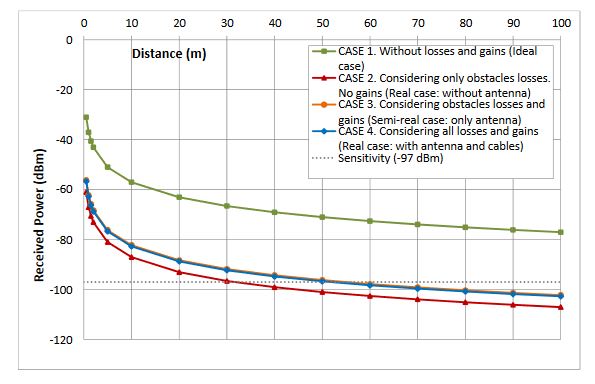
Figure 11. Estimation of maximum distances using Friis formula
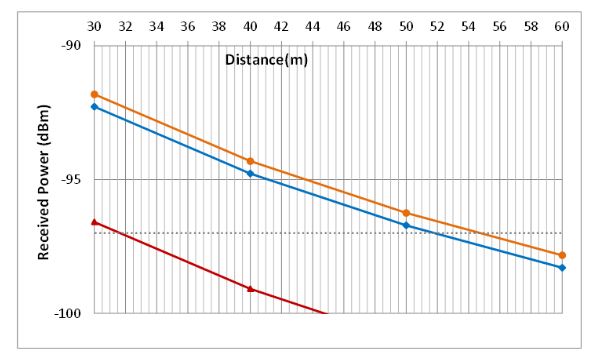
Figure 12. Zoom of maximum distances estimations
The coverage analysis has been studied for different cases. Figures 11 and 12 show the theoretical results obtained when the Friis Equation (4) is used and the parameters of the Table 1 are applied. These results demonstrate that the cable losses are almost irrelevant since cases 3 and 4 are very similar. Furthermore, simulations show that the maximum distance among devices could be more than 50 m since the receiver sensitivity is −97 dBm. However, it is advisable to give a security margin and no to go so closely to the sensitivity value.
CONCLUSIONS AND FUTURE WORK
Taking into account the current simulation results, several conclusions are obtained considering different parts of the proposed scheme. On the one hand, for the decision tree algorithm, it is necessary to select the pruning threshold properly in order to optimize the “unknown” area. A low pruning threshold wastes a lot of space in the features space whereas a high pruning threshold degenerates the learning which causes the extinction of some classes (Figure 13).
The optimization of the pruning threshold is mandatory due to the fact that learning capabilities increase when the “unknown” area is optimized. Something similar occurs with clustering threshold. The selection of an adequate threshold affects largely the number and the definition of new objects that the system is able to detect. A low clustering threshold implies the detection of too many objects that in fact belong to the same category. In contrast, a high clustering threshold produces the detection of objects which are poorly defined (Figure 14).
Therefore, an appropriate selection of the clustering threshold may help the learning process since the system could learn homogenous objects that are properly defined. The presented results also demonstrate that the system, using the complete learning architecture, is able to learn new objects. However, it is unable to classify them as long as a high number of instances are learned. This effect is due to the fact that the number of learned instances for one object has to be comparable to the number of instances of the rest of the trained objects.
Otherwise, the decision tree algorithm will assume that the object is a strange object and it will be classified as “Unknown”. Furthermore, in order to allow the system to evolve and to learn correctly, it is mandatory to adjust the pruning threshold. This adjustment could be automatic taking into account the number of instances of the training set and the number of different objects to classify.
Source: Technical University
Authors: Monica Villaverde | David Perez | Felix Moreno