ABSTRACT
Face recognition and lip localization are two main building blocks in the development of audio visual automatic speech recognition systems (AV-ASR). In many earlier works, face recognition and lip localization were conducted in uniform lighting conditions with simple backgrounds. However, such conditions are seldom the case in real world applications.
In this paper, we present an approach to face recognition and lip localization that is invariant to lighting conditions. This is done by employing infrared and depth images captured by the Kinect V2 device. First we present the use of infrared images for face detection. Second, we use the face’s inherent depth information to reduce the search area for the lips by developing a nose point detection.
Third, we further reduce the search area by using a depth segmentation algorithm to separate the face from its background. Finally, with the reduced search range, we present a method for lip localization based on depth gradients. Experimental results demonstrated an accuracy of 100% for face detection, and 96% for lip localization.
INPUT VIDEO STREAM

Figure 2.1: Sample Color Images Captured from Kinect V2
In each session, the subject was asked to recite the digits from 0-9 in English in front of the Kinect V2. For each digit, 30 frames of color, depth and IR data were captured simultaneously at 30 frames per second (fps). Additionally, each person faces directly at the Kinect within 0.5-4.5 meters from the Kinect. Sample color images from the database are shown in Figure 2.1.

Figure 2.2: Kinect Coordinate System
In each recording session, the raw depth data for each of the 30 frames are captured onto individual text files. The depth data, shown in the z axis in Figure 2.2, represents the distance from the Kinect V2 to the object of interest using the time of flight (ToF) technology. Time of Flight technology in imaging devices computes distances by measuring the time it takes for a light signal to travel between the device and the object.
FACE DETECTION
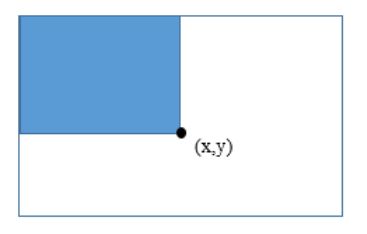
Figure 3.1: Integral Image at Point (x,y)
Detection within the Viola Jones algorithm begins with computation of simple rectangular features that serve as simple classifiers. The features used in the algorithm are rectangular filters that resembles the Haar wavelets. These features are computed using integral images. Each pixel of the integral image I(x,y) is represented by a sum from above and left of the pixel location (x, y, inclusive) from the original image i(x,y) in Figure 3.1.

Figure 3.3: Viola Face Detection for (Left) Color Image and (Right) IR Image in B right Lighting Condition with One True Positive Detected for Each
Post image alignment, we implement the Viola Jones algorithm twice, once for color and another for the IR image based on section 3.3. In this experiment, we want to compare performance results between color and IR face detection in varying illumination conditions from light to dark. True positives denotes a bounding box that was correctly placed on the face, while false positive denotes incorrectly placed boxes.
FEATURE EXTRACTION: LIP LOCALIZATION
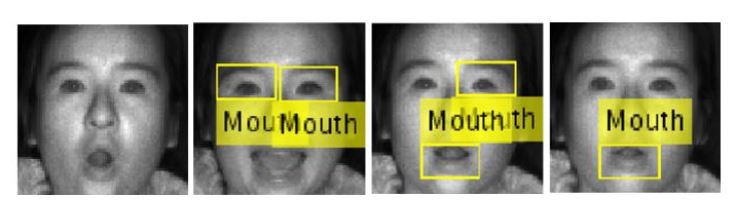
Figure 4.1: False Negative Detection Results from Viola Jones Mouth Detection Given IR Face Input in P2
True positive denotes a mouth that is fully enclosed within the bounding box, and false positive denotes any bounding box that does not enclose the mouth. In addition, false positive also included bounding boxes that include partial mouth and nose. Images where no bounding box completely encloses the mouth are regarded as false negative. Sample images of false negatives within the IR face images are shown in Figure 4.1. The results from Figure 4.1 indicates how the Viola Jones Mouth Detection failed to detect a complete mouth when the subject has their mouth open.
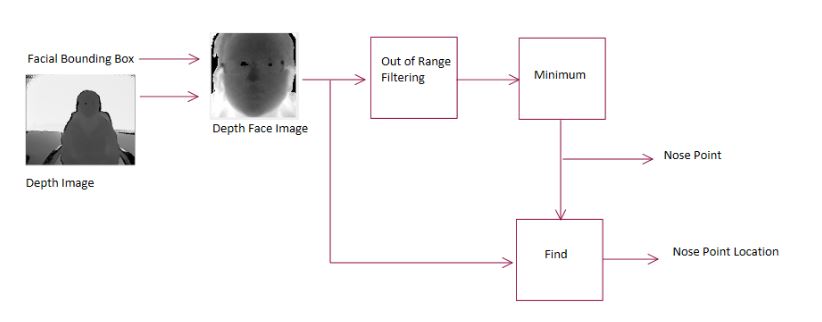
Figure 4.6: Simple Nose Point Detection Block Diagram
For a simple nose point detection algorithm shown in block diagram form in Figure 4.6, three main blocks are needed. Out of Range Filtering removes all indices with values that are out the range of 500 to 4500 mm. Next, the min() function from MATLAB is used to find the smallest depth value of the filtered depth face image. Once the minimum depth is found, the find() function from MATLAB is used to locate pixel location of the minimum depth value from the depth face image.
SYSTEM PERFORMANCE, CONCLUSION AND FUTURE WORK
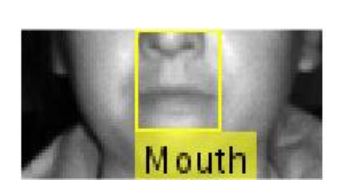
Figure 5.1: Inaccurate Below Nose Face Image
The word, true from the column corresponding to the inaccurate below nose face image in Table 5.1 represents occurrences where such image contains the nose pixels such as Figure 5.1 or any other face pixels above the nose. This allows us to investigate how accurate our ROI reduction was from the Lower Facial Bounding Box algorithm. Although only 8 out of 2700 nose points were inaccurately detected, 24 frames with accurate nose point failed to reduce the facial image to below the nose region.
CONCLUSION
In this thesis, we investigate the use of depth and IR to see if the use of these two streams are plausible for face detection and lip localization algorithms. From the lighting perspective, we see an advantage of using the IR image as compared to color image for places that has low level of light. When given the IR face bounding box coordinates, we took advantage of how the IR and depth stream share the same coordinate system, and compare the two streams for mouth detection.
Given the depth face image, we were able to reduce the ROI for the mouth based on depth gradients. From the result of depth based lip localization, it proved that using depth did indeed increase the detection performance. Based on the results presented in this thesis, we believe that the inclusion of depth based gradient and the use of IR images can further improve the accuracy of lip feature extraction.
Source: California Polytechnic State University
Author: Katherine KaYan Fong
>> Matlab Projects Fingerprint Recognition and Face detection for Final Year Students
>> More Matlab Projects on Signals and Systems for Engineering Students