ABSTRACT
Performance of automatic speech recognition (ASR) systems utilizing only acoustic information degrades significantly in noisy environments such as a car cabins. Incorporating audio and visual information together can improve performance in these situations. This work proposes a lip detection and tracking algorithm to serve as a visual front end to an audio-visual automatic speech recognition (AVASR) system.
Several color spaces are examined that are effective for segmenting lips from skin pixels. These color components and several features are used to characterize lips and to train cascaded lip detectors. Pre and post-processing techniques are employed to maximize detector accuracy. The trained lip detector is incorporated into an adaptive mean-shift tracking algorithm for tracking lips in a car cabin environment. The resulting detector achieves 96.8% accuracy, and the tracker is shown to recover and adapt in scenarios where mean-shift alone fails.
RELATED WORK
Research in computer vision and object detection has been popular in recent years. In particular, machine learning techniques have shown to be useful for object detection. These techniques seek to convert data into information by extracting patterns from data training sets, which can be supervised (labeled) or unsupervised (unlabeled). Popular machine learning algorithms include K-means, random trees, boosting, and neural networks.
COLOR ANALYSIS

Figure 1 : Example Frames from AVICAR
The analysis was performed by first capturing frames in AVICAR where the subject’s lips are visible from all four camera angles. Figure 1 shows an example frame used in the color analysis which measures 720 pixels wide by 480 pixels high. The frame is separated into four frames, each measuring 360 pixels wide and 240 pixels high.

Figure 2 : Separated Frames with Faces Removed
Figure 2 shows an example of separated frame with the face removed. These frames were used to analyze the background color content. For the purposes of this analysis, the subjects hair and bodies were treated as backgrounds.
LIP DETECTION
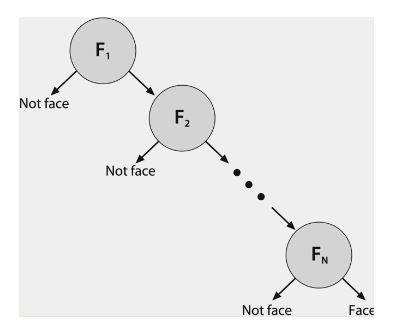
Figure 14 : Structure of Rejection Cascade
A positive detection occurs if the final stage classifies a region as positive. As such, this type of classifier is also known as a rejection cascade. Figure 14 shows the basic structure of a face detector rejection cascade; a lip detector rejection cascade would follow the same structure.
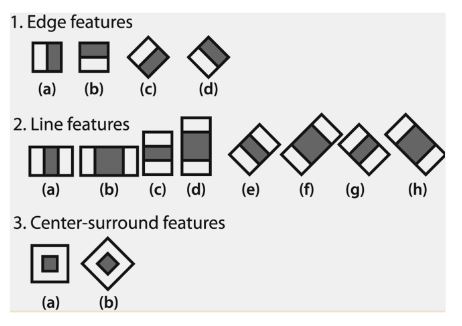
Figure 15 : Example of Haar-like Rectangular Features
Figure 15 shows examples of Haar-like features whose values are calculated as the pixel values in the light rectangles subtracted from the dark rectangles. Although there are only three types of Haar-like features, the entire set of rectangle features includes roughly 180,000 different features.
MEAN-SHIFT TRACKING
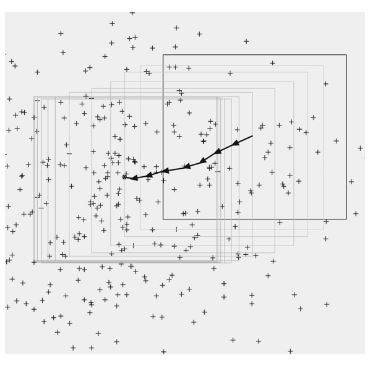
Figure 49 : Mean-Shift Performed on Array of Data Points
Intuitively, the tracking window seeks out and centers itself on its center of mass. This is illustrated in Figure 49, which shows an example of the MS algorithm applied to a two-dimensional array of data points. The window starts in a position with an uneven distribution of points.

Figure 51: Lost Target
The event corresponding to the dip seen near frame 851 is shown in Figure 51. In these frames, the frame number is printed in the top left, and the lip box indicates the tracking window. The lips were initially tracked correctly, but beginning in frame 835, the subject quickly turns her head. The movement was quick enough to move her lips outside of the tracking window.
CONCLUSION AND FUTURE WORK
We have maximized the lip detector accuracy using several pre and post-processing techniques. For pre-processing, histogram equalization using 256 bins combined with image sharpening improved the HOG TPR by 7.5% over baseline with minimal impact on accuracy. Post-processing using size selection and Bayesian classification produced identical accuracy, but size selection was ultimately chosen for its simplicity. We have also shown that features like HOG, Haar, and LBP rely on differences in intensity values to effectively describe targets.
These features are illumination invariant by design. Thus, training cascaded classifiers using luminance values are more effective for lip detection than using chrominance components, since chrominance components eliminate details that can be used as features. Furthermore, using HOG to characterize lips created a lip detector 26% more accurate than using Haar features, and 13% more accurate than using LBP.
Source: California Polytechnic State University
Author: Benjamin Wang