ABSTRACT:
The state of the art in design and development flows for FPGAs are not sufficiently mature to allow programmers to implement their applications through traditional software development flows. The stipulation of synthesis as well as the requirement of background knowledge on the FPGAs’ low-level physical hardware structure are major challenges that prevent programmers from using FPGAs.
The reconfigurable computing community is seeking solutions to raise the level of design abstraction at which programmers must operate, and move the synthesis process out of the programmers’ path through the use of overlays. A recent approach, Just-In-Time Assembly (JITA), was proposed that enables hardware accelerators to be assembled at runtime, all from within a traditional software compilation flow.
The JITA approach presents a promising path to constructing hardware designs on FPGAs using pre-synthesized parallel programming patterns, but suffers from two major limitations. First, all variant programming patterns must be pre-synthesized. Second, conditional operations are not supported.
In this thesis, I present a new reconfigurable overlay, URUK, that overcomes the two limitations imposed by the JITA approach. Similar to the original JITA approach, the proposed URUK overlay allows hardware accelerators to be constructed on FPGAs through software compilation flows. To this basic capability, URUK adds additional support to enable the assembly of presynthesized fine-grained computational operators to be assembled within the FPGA.
This thesis provides analysis of URUK from three different perspectives; utilization, performance, and productivity. The analysis includes comparisons against High-Level Synthesis (HLS) and the state of the art approach to creating static overlays. The tradeoffs conclude that URUK can achieve approximately equivalent performance for algebra operations compared to HLS custom accelerators, which are designed with simple experience on FPGAs. Further, URUK shows a high degree of flexibility for runtime placement and routing of the primitive operations.
The analysis shows how this flexibility can be leveraged to reduce communication overhead among tiles, compared to traditional static overlays. The results also show URUK can enable software programmers without any hardware skills to create hardware accelerators at productivity levels consistent with software development and compilation.
BACKGROUND
This chapter provides an overview of reconfigurable hardware architectures including Field Programmable Gate Arrays(FPGAs) and Coarse-Grained Reconfigurable Architectures(CGRAs). Additionally, the compilation flow and the productivity challenges of FPGAs are discussed. Then, it presents the effort of the reconfigurable computing community on raising the design abstraction level and increasing productivity.
FPGAs Overview:
Field-Programmable Gate Arrays (FPGAs) are electrically programmable silicon devices that can be configured to implement almost any complex digital circuits or systems. An FPGA is a two dimensional array of logic units and electrically programmable routing interconnects.
Logic units comprise Configurable Logic Blocks(CLBs), Digital Signal Processors (DSPs), Block RAMs (BRAMs), Input-Output Buffers (IOBs), and Digital Clock Managers (DCMs). These logic units can be configured and connected to implement different combinations of sequential and combinational circuits to provide different functionalities ranging from one simple gate to a sophisticated microprocessor.
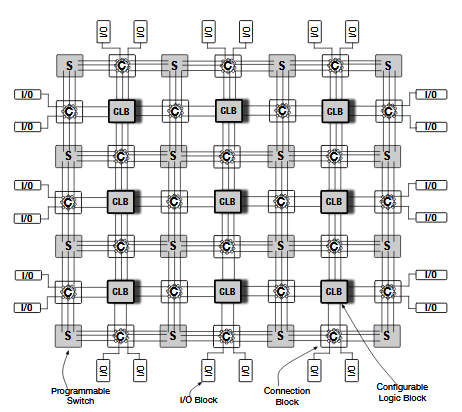
General FPGA Architecture.
CGRAs Overview:
Coarse-Grained Reconfigurable Architectures(CGRAs) have been proposed as an alternative to the fine-grain architectures (FPGAs) to support faster compilation through raising the level of reconfigurability from bit-width to word-width granularity, which enables on-the-fly customization and reduces configuration overload.
Particularly, CGRAs are designed to be customized on ASIC for specific applications that have inherent data-parallelism. CGRAs are mainly composed of Processing Elements(PEs), that include ALUs, multipliers, and shift registers connected by word width mesh-like interconnects and are controlled by resources managers and synchronization modules.
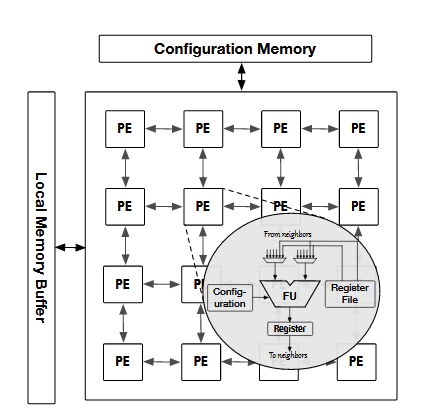
General CGRA Architecture.
High Level Synthesis:
The increase in silicon capacity and System-On-Chip (SOC) complexity has shifted interest toward a higher level of abstraction which is considered on of the powerful ways of regulating complexity and enhancing design productivity.
The reconfigurable computing community has addressed the productivity challenges within FPGAs design flow and tried to raise the abstraction level beyond Register Transaction Level (RTL) by using High Level Synthesis (HLS). The HLS tools translate untimed or partially timed functional specifications written in one of the high level languages such as C, C++, SystemC, Haskell, ..etc into low level fully timed RTL specifications.
Overlays:
Intermediate Fabrics, or overlays, have been proposed to allow higher level computational components such as soft processors, and vector processors, as well as Course Grained Reconfigurable Arrays (CGRAs) type structures, to be embedded within FPGAs.
The potential advantage of such overlays is that circuits and hardware acceleration can be achieved through compilation instead of synthesis on existing FPGAs. Conventional approaches for enabling CGRAs on an FPGA are to replace LUTs and Flip Flops with small programmable computational units like ALUs as the compilation target.
Domain Specific Languages:
Domain Specific Languages(DSLs) (e.g. Python, Snort, HTML) are common within software development. DSLs promote the use of languages tuned for the needs of specific application domains. Once created and tuned, the language promotes increased programmer productivity through appropriate abstractions and heavy reuse.
JUST-IN-TIME ASSEMBLY
Introduction:
The earlier work by Sen Ma, Just-In-Time Assembly (JITA) aims to move the synthesis process out of the programmers’path, increase application developers productivity, and support design portability between different FPGA vendors and parts. JITA approach takes advantage of partial reconfiguration technology to compose custom accelerators on the fly by using pre-built bitstreams. Since this work is extending the JITA approach, this chapter is dedicated to provide background description about the JITA.
JITA Approach:
The JITA approach aims to increase the FPGAs’ programmers productivity by moving the synthesis, place and route processes out of their path through composing pre-synthesized small bitstreams to form full custom accelerators.
Under traditional FPGA design flows the programming patterns are combined into a single object, and then object is synthesized. Each time the functionality in the source code is changed to create a new object, it must be re-synthesized. This keeps synthesis, place and route in the development path of the programmer.
Design Approach.
Compilation Flow:
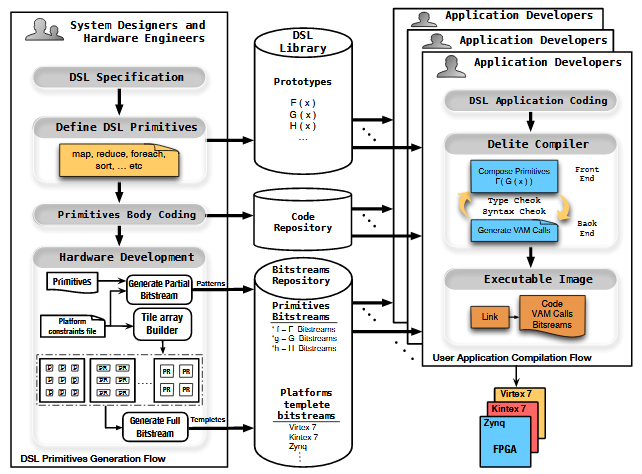
The JITA uses the Delite Framework to create a new DSL. This is then compiled into for the overlay. It shows how Delite supports two classes of users; system programmers and hardware engineers that create the DSL use the flow on the left, and application programmers use the flow on the right. Creating a standard DSL on the left involves defining and coding the programming patterns.
JITA Overlay:
The JITA overlay was pre-formed programmable components built on top of an FPGAs lookup tables and flip-flops. The overlay was occupied with tile array and Black RAMs. The overlay includes a nearest neighbor programmable word width interconnect similar to traditional CGRA type overlays. Different from traditional CGRA overlays, the JITA overlay exposes the lookup tables and flip flops of the FPGA as partially reconfigurable tiles instead of abstracting them into programmable computational units.
Run Time Interpreter:
The JITA has a run time mechanism to interpret the function calls generated by the compiler to compose accelerators. Using the interpreter allows the data flow graph information generated by the back end of the DSL compiler to remain portable, similar to portable Java Byte Code. It shows the instructions the compiler produces to represent the data and control flow graphs. The output of the backend generator called Virtual Accelerator Machine (VAM) language.
PROPOSED SOLUTION
Hardware Design Flow:
The hardware design flow consists of two parts. First, creating the overlay static logic shown in the right side. In our design, the creation of the overlay static logic is scripted and parametrized to produce overlays with different settings. For instance, the number of tiles can be specified to 2×2 or 3×2 or any other dimensions depending on the target FPGA size. Besides, the PR region size parameters specifying the PR regions size for each tile.

Hardware Design Flow for the Overlay Static Logic and Partial Bitstreams.
URUK Architecture:
URUK overlay is structured to compose a wide variety of accelerators using pre-synthesized operators and parallel patterns benefiting from the partial reconfiguration technology. In URUK overlay,the candidate function for acceleration is partitioned into fundamental operators(add, sub, mul,div, and, or, not, and xor) and standard parallel patterns. These operators and patterns are pre synthesized and stored into a bitstream library.
URUK COMPILATION FLOW
URUK Parallelism:
Within URUK overlay, parallelism can be achieved by instantiating additional copies of the application throughout additional tiles. This is like unrolling a loop which translates temporal iterations into spacial parallelism. Each copy will have the same DFG patterns of the original one. Besides, The source data should be divided among them be processed in parallel, then the results should be collected back from the tiles that hold the results.
Conditional Operations:
Conditionals were a barrier that prevents composing patterns in the original JITA. Some DFGs have conditional branching which was a limitation in the original JITA approach. Within URUK overlay, branches are handled by swapping a comparator bitstream into a tile PR region, supplying the inputs, and feeding the PR region’s output to the status register within the same tile.
Based on the status of the flag, the next command will change the direction of data, or change the execution sequence by modifying the Program Counter (PC) and jump to a specified address.
Domain Specific Langauges:
This section provides a brief introduction about possible Domain Specific Languages (DSLs) that can serve as developing applications as well as compiling for the overlay. DSLs (eg. Python, Snort,HTML) are common within software development. DSLs promote the use of languages tunedfor the needs of specific application domains.
EVALUATION
This chapter presents an evaluation of the thesis’ claims and questions put earlier The newly designed overlay, URUK, is programmable and able to compose pre-synthesized programming patterns as well as pre-synthesized computational perators. Additionally, the thesis claims the new overlay can handle conditional operations.
Thus, we chose benchmark functions that include patterns and operators with conditionals to evaluate these claims. Next, the bench-mark functions are implemented on the overlay using patterns then using operators to measure the impact of replacing patterns by operators on resource utilizations and performance.
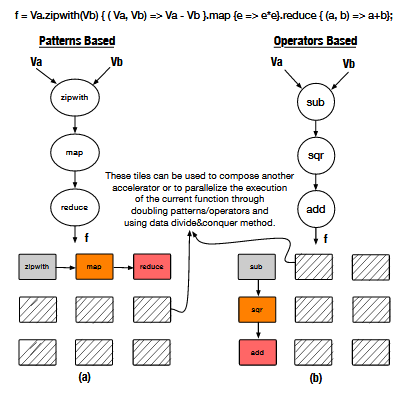
The DFG of CP1 Function Based on Pre-synthesized (a) Patterns and (B) Operators, and the Placement on 3×3 Overlay.
FUTURE WORK
The presented overlay architecture and the compilation flow hold potential for additional constructions and several other optimizations, which can be considered in the future. First, a DSL compiler need to be developed by integrating a backend generator into the Delite Framework or similar platform.This stage includes several critical steps to enhance the overlay performance and utilizations. For instance, integrating a search algorithm for efficient place and route.
Second, the diminution of the overlay can be increased and distributed across multiple FP-GAs for large scale computations.This will allow achieving high parallelism and optimizing the performance especially when the computational task is extensive, and the data set is very large.
Third, to optimize the resource utilization of the overlay, tiles’ PR regions can be set to variant sizes. This will reduce the resource’s internal fragmentations. Further, since the overlay is dynamic, it is crucial to explore other interconnect topologies, which may provide more efficient overlay structure.
Source: University of Arkansas
Author: Zeyad Tariq Aklah